期货账户分析系统数据存储升级方案选型
先介绍下我经手的两款分析系统产品存储方案
期析账户分析系统
在2013年左右开发“期析账户分析系统”时,图省事采用了mongodb,以一组replicaset(4台)的方式跑了几年。随着数据逐步增多,弊端逐笔显现,主要的弊端体现在:
- 随着数据量增多,数据入库效率极低,特别是当单表的索引超过服务器内存时;
- 程序虽然采用了主节点写入,从节点读取的方式,效率依然不高(因为从节点须不断从主节点同步数据)
- 太浪费服务器资源,schema free是nosql的卖点,同时也是其弊端(占用大量的存储资源)
应该说,在mongodb上还有优化的空间,比如将现有的4台拆分成2个replicaset节点,只是这几年跑下来真心觉得mongodb的性价比太低,不想继续折腾更不想增加数据库维护的复杂度。
期析排行榜
公司的另外一款产品“期析排行榜系”统采用的是mysql分表存储形式,通过程序自动计算数据出入库的分表。这种存储方式的弊端是:
- 不同的表存储的数据量不同,拆分数据均匀度比较差;
- 随着数据量增大,须进行二次拆分,否则单表(分表)的数据量太大仍然影响数据效率,二次拆分时除了数据库升级还得升级程序;
- 分表之间无法直接横向查询,只能通过程序实现汇总;
- 程序复杂度增加。
注:本产品开发与2010年,当时的mysql尚不支持分区方案
数据库升级方案
1. 期析排行榜系统
实际当前的Mysql版本已经支持list、hash、range、key分区了,因此期析排行榜系统直接升级mysql版本,并利用分区替分表(程序拆分)应该是成本最小的升级方案。还有最主要的是,期析排行榜系统的客户大部分数据量并不是特别大,二拆的可能性较小(据我了解,截止2021年3月mysql应该不支持对分区再分区)。
2. 期析账户分析系统
期析账户分析系统的主要用户是期货公司和期析平台本身。其数据量远远超过排行榜系统的用户。而且随着时间推移,分区二拆、三拆的可能性很大。因此pgsql成了必然的选择——pgsql13支持range、list、hash分区,而且支持对分区无限级拆分,最重要的是分区的子分区可以采用不同分区方案(比如一级分区采用list分区,而二级分区可以采用不同的rang、hash分区)。
选择pgsql的主要理由
- 支持分区功能,而且可以无限级、自有组合分区方案;
- 对于不同数据表存储的数据,根据其重要性,可以通过在创建数据表时指定表空间将数据存储到不同的位置。比如可以将备份数据存储到普通磁盘,将高频访问的数据存储到高速磁盘上。硬盘空间满了亦可通过表空间进行迁移,关于表空间可以参考:tablespace;
- pgsql支持json数据格式存储,在存储数据时可以用json或者jsonb格式。而两者唯一的区别在于效率,json是对输入的完整拷贝,使用时再去解析,所以它会保留输入的空格,重复键以及顺序等。 而jsonb是解析输入后保存的二进制,它在解析时会删除不必要的空格和重复的键,顺序和输入可能也不相同。json格式的支持使得pgsql完美支持schema free数据类型,很好地替代nosql;
- 对于海量数据方面,如果有一天pgsql真的撑不住了,greenplum可以无缝对接。
升级方案
最终的升级方案是:根据不同表的数据量,采用账户字符串的hash分区进行拆分,步骤参考下文。
- 从原有的数据表复制结构:
create table if not exists new_table (like old_table including all) partition by hash(xxx);- 根据不同表的数据量,创建不同的分区数,下列创建5个分区表:
do language plpgsql $$
declare
p5 int := 5;
begin
for i in 0..p5-1 loop
execute format('CREATE TABLE IF NOT EXISTS new_table_p%s PARTITION OF new_table FOR VALUES WITH (MODULUS %s, REMAINDER %s)', i, p5, i);
end loop;
end;
$$;- 将数据拷贝到新表:
insert into new_table select * from old_table;注:如果原先的表存在非分区字段的自增id或者非分区字段的唯一索引,则在创建新表时会失败,这时候可以利用原表的DDL进行创建。
下列可以看下利用hash分区方案的数据分布均匀度测试:
10个分区
select tableoid::regclass, count(*) from account group by tableoid::regclass order by tableoid::regclass;
20个分区
select tableoid::regclass, count(*) from account_hash20 group by tableoid::regclass order by tableoid::regclass;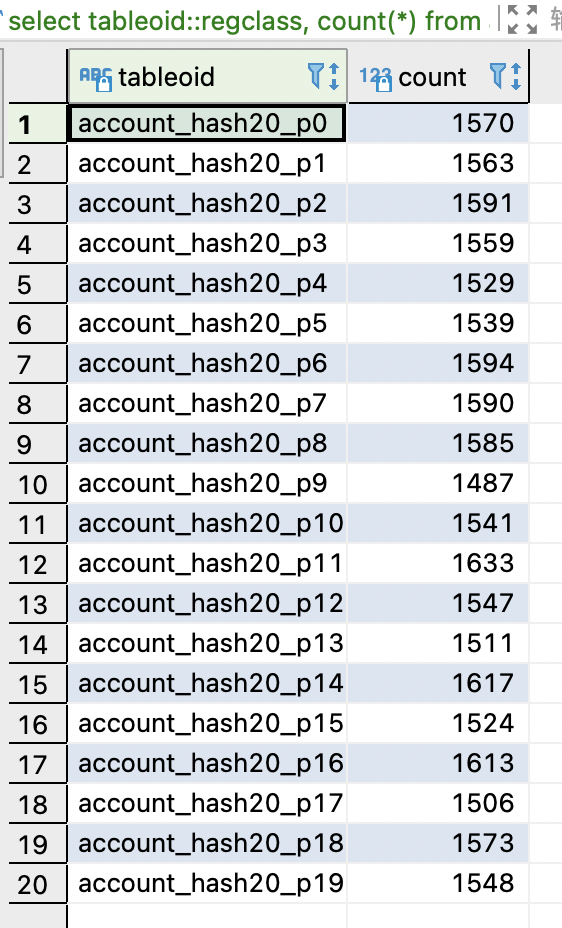
 说点什么
说点什么
博主